

En los últimos años, los modelos generativos de imágenes han transformado el campo de la inteligencia artificial, permitiendo a cualquier usuario describir una escena con palabras y obtener una imagen sorprendentemente realista. Sin embargo, esta revolución ha tenido dos limitaciones claras: el tamaño de los modelos y el coste computacional que requieren. El proyecto Z-Image, desarrollado por Tongyi MAI Lab de Alibaba, aborda ambos desafíos de forma elegante y eficaz.
🌐 ¿Qué es Z-Image?
Z-Image es un modelo de generación de imágenes basado en una arquitectura denominada Single-Stream Diffusion Transformer (S3-DiT). A diferencia de otras técnicas de difusión clásicas que separan componentes de texto y visuales, este enfoque unifica todos los insumos —texto, embebidos semánticos y latentes ruidosos— en una única secuencia para el Transformer. Esto permite una eficiencia sorprendente y mejores resultados en muchos escenarios.
Con solo 6 mil millones de parámetros, Z-Image logra resultados comparables a modelos mucho más grandes, democratizando así el acceso a generación de imágenes de alta calidad incluso en hardware de consumo.
🧠 Arquitectura y Principios Clave
🔹 Single-Stream Diffusion
La innovación arquitectónica principal es que todas las entradas condicionantes (texto, imágenes, latentes) se concatenan y procesan juntas dentro de un único Transformer. Esto reduce redundancias y maximiza la eficiencia de cómputo sin sacrificar calidad.
🔹 Optimización del rendimiento
El modelo ha sido cuidadosamente optimizado para equilibrar rendimiento visual y costos computacionales. Esto queda claro en sus variantes, que presentan un espectro de capacidades pensadas para usos distintos:
- Z-Image-Turbo: versión destilada que genera imágenes fotorealistas con sub-segundos de latencia y excelente precisión de texto —incluyendo textos bilingües en chino e inglés— con muy pocos pasos de inferencia.
- Z-Image-Base: el núcleo “no destilado”, ideal como base para ajustes finos y trabajos más detallados.
- Z-Image-Edit: variante enfocada en edición de imágenes a partir de instrucciones textuales específicas.
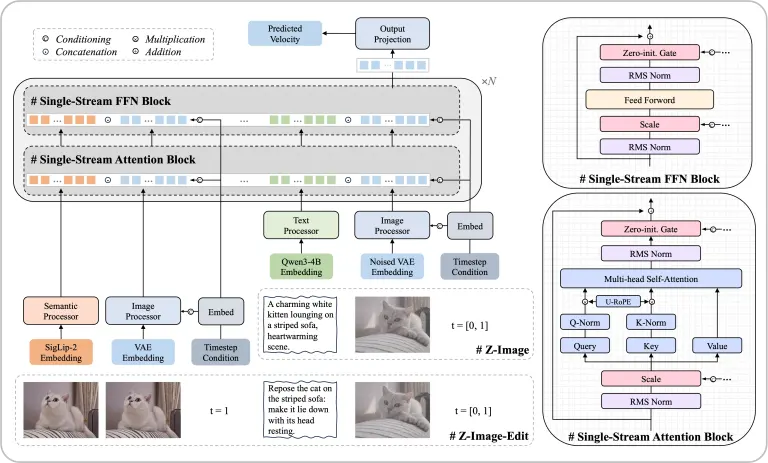
Estas versiones proporcionan una escalera de herramientas desde prototipado rápido hasta producción creativa e investigación avanzada.
🎯 Resultados y Aplicaciones
📸 Calidad fotográfica y representación de texto
Z-Image-Turbo destaca por su capacidad para generar imágenes con nivel fotográfico y texto legible dentro de la imagen —un reto clásico para los modelos de difusión tradicionales—, especialmente al trabajar con tipografías complejas o textos bilingües.
🌍 Conocimiento del mundo y comprensión semántica
El modelo no solo interpreta palabras clave, sino que incorpora una comprensión más profunda de los conceptos culturales y contextuales del mundo real, lo que se traduce en imágenes más coherentes y relevantes.
🔄 Edición guiada por lenguaje
Con Z-Image-Edit, es posible modificar imágenes existentes siguiendo descripciones en lenguaje natural: cambiar estilos, expresiones, colores o composición general sin necesidad de herramientas manuales complejas.
🧩 Importancia para la comunidad
Z-Image demuestra que no siempre hace falta escalar parámetros para lograr calidad rivalizando con modelos propietarias más grandes. Al liberar el código, pesos y demos, el equipo de Tongyi MAI contribuye a que investigadores y desarrolladores construyan y experimenten con herramientas de generación de imágenes de vanguardia sin depender de enormes infraestructuras de cómputo.
Este enfoque es un paso importante hacia un ecosistema de IA más accesible, sostenible y colaborativo.
💭 Conclusión
Z-Image representa una evolución importante en los modelos generativos de imágenes: combina eficiencia, calidad fotorealista y comprensión semántica profunda en un solo paquete compacto y accesible. Su arquitectura innovadora y su conjunto de variantes lo posicionan tanto para aplicaciones creativas como para investigación avanzada.
A medida que la comunidad explore y expanda este modelo, es probable que veamos nuevas aplicaciones creativas, ediciones guiadas por lenguaje cada vez más sofisticadas y herramientas integradas en productos creativos digitales.
🧪 Tutorial práctico: usar Z-Image para generar imágenes
🧠 Requisitos previos
- Python 3.9+
- GPU con CUDA (recomendado, aunque puede funcionar en CPU)
- Conocimientos básicos de IA generativa / Diffusion
1️⃣ Instalación del entorno (Python)
git clone https://github.com/Tongyi-MAI/Z-Image.git
cd Z-Image
pip install -r requirements.txt
Si usas CUDA, asegúrate de tener:
torchcon soporte CUDA- Drivers NVIDIA actualizados
Comprobación rápida:
import torch
print(torch.cuda.is_available())
2️⃣ Cargar el modelo Z-Image-Turbo
Esta es la versión ideal para uso real: rápida, pocos pasos y alta calidad.
from diffusers import DiffusionPipeline
import torch
pipe = DiffusionPipeline.from_pretrained(
"Tongyi-MAI/Z-Image-Turbo",
torch_dtype=torch.float16
).to("cuda")
🔎 Nota didáctica: Z-Image usa una arquitectura single-stream, por lo que texto y latentes se procesan juntos. Esto reduce pasos y latencia.
3️⃣ Generar una imagen desde texto
prompt = "A futuristic cyberpunk city at night, ultra realistic, cinematic lighting"
image = pipe(
prompt,
num_inference_steps=4, # Muy pocos pasos 🚀
guidance_scale=2.0
).images[0]
image.save("zimage_result.png")
💡 En clase remarcaría:
- 4–8 pasos ya producen resultados de calidad
- Menor
guidance_scale= más libertad visual
4️⃣ Texto dentro de imágenes (uno de sus puntos fuertes)
prompt = 'A neon sign that says "TONIDOMENECH.SPACE" in a cyberpunk street'
image = pipe(prompt).images[0]
image.save("texto_legible.png")
✔ Z-Image destaca en tipografía coherente, algo históricamente difícil en diffusion.
5️⃣ Edición de imágenes con Z-Image-Edit
Ejemplo conceptual (si partes de una imagen):
prompt = "Change the sky to a dramatic sunset with red clouds"
image = pipe(prompt, image=base_image).images[0]
🧠 Ideal para:
- retoque creativo
- marketing visual
- diseño web y branding
6️⃣ Uso visual con ComfyUI (sin código)
Pasos rápidos
- Instala ComfyUI
- Copia el modelo Z-Image en:
ComfyUI/models/checkpoints/ - Carga un workflow de Diffusion Transformer
- Ajusta: Steps: 4–6 CFG: 1.5 – 3
- Steps: 4–6
- CFG: 1.5 – 3
- Prompt → Generate
🎯 Ventaja para alumnos y creativos: experimentación visual inmediata